バイオマーカーの開発補助の事例を公開しました
業種:研究機関
目的:機械学習モデルを用いた脳腫瘍・がん疾患等の特徴的塩基配列のパターン把握
本プロジェクトにおいては脳腫瘍患者の診断に役に立つバイオマーカー開発のため、脳腫瘍患者が持つ特徴的な塩基配列を見出すことを目的として、機械学習の様々なモデルを用い疾患の深刻度合いを識別するモデルの開発を行いました。
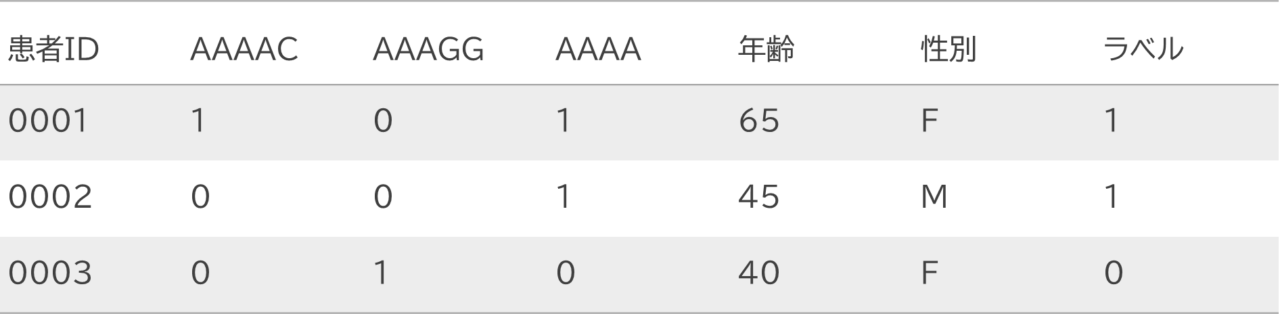
使用データ
塩基パターンと患者の属性;疾患の深刻度合いのデータを解析に用いました。
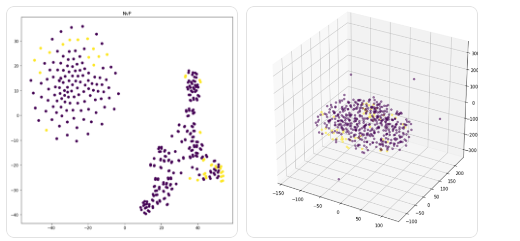
実施したアプローチ
患者の疾患の深刻度合いを目的変数、塩基配列を特徴量とし教師あり機械学習を実行しました。予測精度の高いモデルが得られれば、そのモデルにおいて高い重要度を示す塩基配列に疾患特有のものがあるかを検討することが出来ます。データは学習データ:検証データ=8:2で分割し、検証データを使ってモデルの評価を行いました。また、本ケースにおいてはデータの次元が膨大(10万以上)であり、いわゆるスパースモデリングや次元収縮についても複数のアプローチを検討しました。これらの措置を施すことにより、多次元の特徴量でモデルを作成する際に、特徴量を重要なものに絞り、過学習を防ぐことに繋がります。
使用した機械学習モデル
今回は数多ある機械学習モデルのなかからRandomForest, XGboost, CatBoost, LightGBMの4種類を検討し、比較しました。どれもツリーベースのため、それぞれの特徴量がどのくらいGini impurityを下げるか算出することによって、特徴量の重要度(feature importance) を評価することができます。今回は各モデルから重要度上位20の塩基配列を抽出しました。
分析結果
モデルによって、重要度に違いがありましたが、どのモデルでも重要度の高い塩基配列がいくつかありました。これらの配列は、バイオマーカーの開発に役に立つ可能性が高いと考えられます。